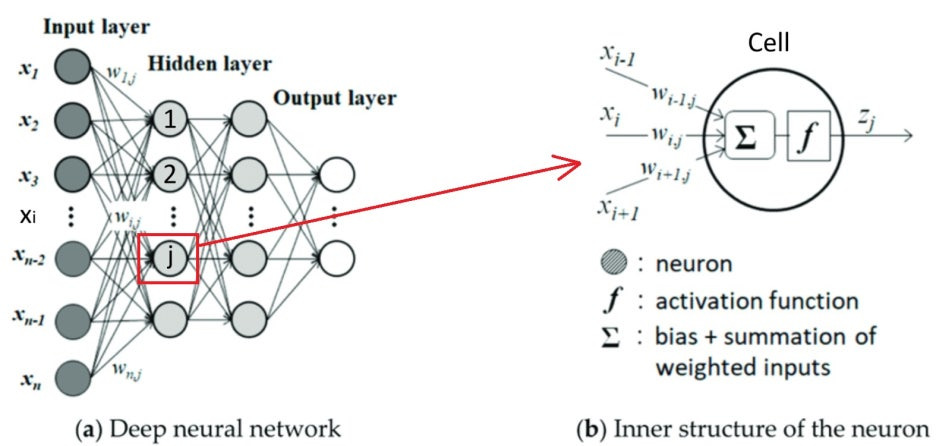
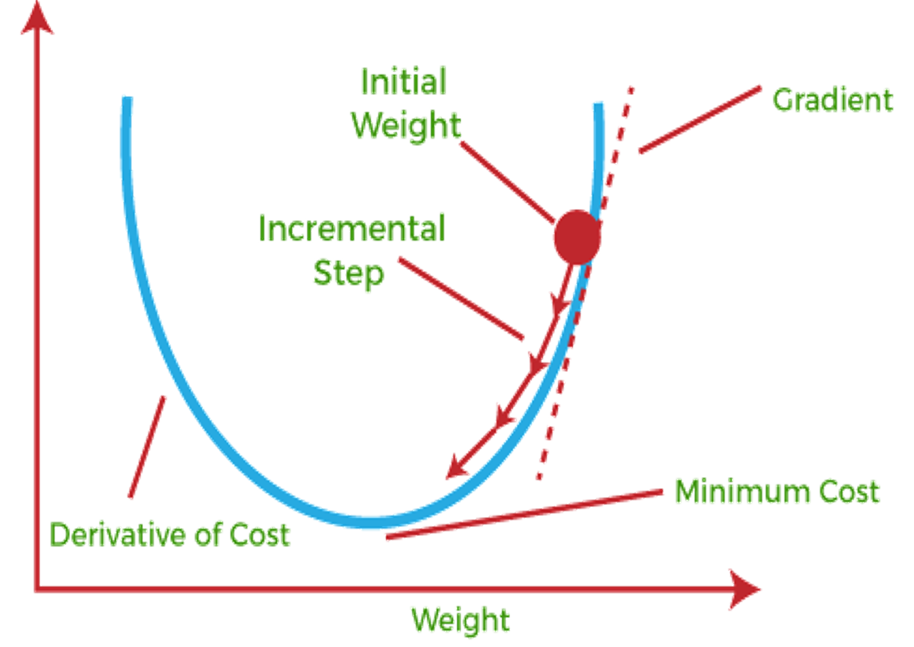
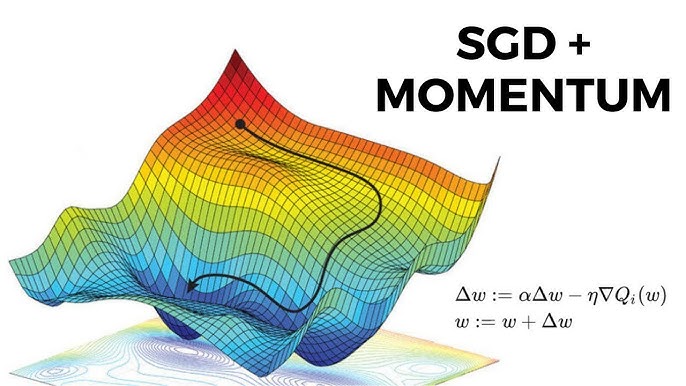
오늘 소개드릴 강의는 본격적인 인공지능 강의입니다. 역시 같은 강사가 가르치는 강의로 2개가 있습니다.
첫번째는 이미지 인식 딥러닝 강의입니다. (https://www.udemy.com/course/computer-vision-a-z/learn/lecture/8127614?start=15#overview)

이 강의는 본격적인 딥러닝 강의로 지난 시간에 소개해드린 머신러닝 강의에서 설명한 딥러닝을 이미지 인식에 적용하는 것을 배우는 강의입니다. 강의 소개문을 보겠습니다.
--------------------------------------------------------------------------------------------------
AI와 딥러닝에 대해 들어본 적이 있을 것입니다. 하지만 이 새로운 산업 혁명에서 내 위치가 무엇인지, 소비자인지 창작자인지 고민해 본 적이 있을까요? 대부분의 사람들에게 그 답은 소비자일 것입니다. 하지만 만약 여러분도 창작자가 될 수 있다면 어떨까요? 여러분이 쉽게 인공지능 세계에 들어가, 최신 기술을 활용한 멋진 응용 프로그램을 만들어 세상을 더 나은 곳으로 바꿀 수 있다면요? 너무 좋은 이야기처럼 들릴 수도 있지만, 실제로 그 방법이 존재합니다.
그 방법 중 하나는 바로 "컴퓨터 비전"입니다. 컴퓨터 비전은 AI 분야 중 가장 쉽게 창작자가 될 수 있는 길입니다. 그리고 그것이 가장 쉬운 길일 뿐만 아니라, AI의 여러 분야 중 가장 많은 창작을 할 수 있는 분야이기도 합니다. 왜 그럴까요? 바로 컴퓨터 비전이 거의 모든 분야에 적용되기 때문입니다. 의료, 소매업, 엔터테인먼트 등 그 범위는 정말 광범위합니다. 이미 컴퓨터 비전 시장은 180억 달러 규모로, 급격히 성장하고 있습니다.
예를 들어, 환자의 MRI 뇌 스캔에서 종양을 탐지하는 기술을 생각해 보세요. 인간보다 10,000배 더 많은 이미지를 분석할 수 있기 때문에, 매일 더 많은 생명이 구해지고 있습니다. 그리고 만약 여러분이 컴퓨터 비전이 아직 적용되지 않은 산업을 찾았다면, 그보다 더 좋은 기회는 없습니다. 그건 바로 여러분이 그 산업에서 새로운 사업 기회를 잡을 수 있다는 뜻이니까요.
그렇다면 이제 어떻게 컴퓨터 비전의 세계에 들어갈 수 있을까요? 지금까지 컴퓨터 비전은 상당히 복잡하고, 그만큼 점점 더 복잡해져 가고 있었습니다. 코드, 라이브러리, 툴이 많아질수록 길을 잃기 쉬워졌습니다. 더욱이 컴퓨터 비전을 활용하려면 그것을 어떻게 사용하는지를 아는 것뿐만 아니라, 그 원리가 무엇인지도 이해해야 최대한 이점을 취할 수 있습니다.
이 문제를 해결하기 위해, 저희는 "컴퓨터 비전 A-Z"라는 강의를 준비했습니다. 이 강의를 통해, 여러분은 가장 인기 있는 컴퓨터 비전 방법들이 어떻게 작동하는지 배우고, 그것들을 실제로 적용하는 방법을 익힐 수 있습니다.
이 강의를 통해 배울 내용은 다음과 같습니다:
- 강력한 컴퓨터 비전 모델들을 다룰 수 있는 도구 상자
- 컴퓨터 비전의 이론 이해
- OpenCV 마스터하기
- 객체 탐지 마스터하기
- 얼굴 인식 마스터하기
- 강력한 컴퓨터 비전 응용 프로그램 만들기
강의에 필요한 조건은 매우 간단합니다. 고등학교 수학 지식과 기초적인 파이썬 프로그래밍 지식만 있으면 됩니다. 이 강의는 컴퓨터 비전이나 인공지능에 관심이 있는 모든 사람을 대상으로 합니다. 여러분도 창작자가 될 수 있는 기회를 놓치지 마세요!
-------------------------------------------------------------------------------------------------
두번째는 강화학습(Reinforcement Learning)과 대규모언어모델(Large Language Model)에 관한 강의입니다.
(https://www.udemy.com/course/artificial-intelligence-az/learn/lecture/12606408?start=1#overview)

강화학습이란 쉽게 말해서 어떤 상황에서 어떤 선택을 하느냐를 결정하는 모델을 학습시키는 것을 말합니다. 간단히 예를 들자면, 2차원 평면에서 일어나는 간단한 게임을 들 수 있습니다. 패크맨(Pacman)의 경우 2차원 미로에서 돌아다니면서 술래들을 피해서 콩을 먹으로 다닙니다. 이때 패크맨이 취할수 있는 행동은 위/아래/우측/좌측 이동 등 총 4가지의 움직임이 있습니다. 그리고 패크맨이 위치한 환경은 2차원 미로와 그 미로를 돌아다니는 술래들입니다.
그래서 패크맨 자신의 위치, 주변 미로의 생김새, 주변 술래의 위치 등을 입력으로하고, 방향선택을 출력으로하는 모델을 만들 필요가 있습니다. 학습을 할때 술래에게 잡히면 벌점, 콩을 먹으면 보상을 주는 방식으로 모델을 '학습'시킵니다. 처음 학습이 되지 않은 생태에서는 멋대로 다니다가 술래에게 잡혀서 벌점을 먹습니다. 하지만 학습이 반복되면, 주어진 상황에서 어떤 방향으로 가야 술래를 피해서 콩을 먹으러 갈수 있는지 스스로 판단하게 됩니다.
대규모 언어모델도 이와 비슷하게 동작합니다. 주어진 입력(주어진 문장)에 대해서 학습한 결과대로 가장 적절해 보이는 문장(응답 문장)을 출력합니다. 이 때 학습에 사용된 수많은 화자간의 대화가 바로 위에서 예를 든 미로, 술래 등에 해당합니다. 그럼 아래에 강의 소개문을 한번 보겠습니다.
--------------------------------------------------------------------------------------------------
인공지능(AI)에 대한 기본 개념을 직관적으로 배우고, 이를 실제로 8개의 다양한 AI를 구축하며 연습할 수 있는 기회를 제공합니다.
이 강좌에서는 다음과 같은 AI를 구축합니다:
- 비즈니스 지원을 위한 기초 모델(LLM)을 활용한 AI 에이전트 구축
- Q-러닝 모델을 사용하여 창고 흐름을 최적화하는 AI 구축
- 심층 Q-러닝 모델을 사용하여 달에 착륙하는 AI 구축
- 심층 컨볼루션 Q-러닝 모델을 사용하여 팩맨 게임을 플레이하는 AI 구축
- A3C(비동기적 이점 액터-크리틱) 모델을 사용하여 Kung Fu 전투 AI 구축
- PPO(근접 정책 최적화) 모델을 사용하여 자율 주행 자동차 AI 구축
- SAC(소프트 액터-크리틱) 모델을 사용하여 자율 주행 자동차 AI 구축
- 강력한 사전 훈련된 LLM(Llama 2 by Meta)을 미세 조정하여 의학 용어에 대해 대화할 수 있는 AI 의사 챗봇 구축
이것이 전부가 아닙니다. 강의를 완료하면 3개의 추가 AI도 받을 수 있습니다: DDPG, 풀 월드 모델, 진화 전략 및 유전자 알고리즘. 이 AI들은 자율 주행 자동차와 휴머노이드 애플리케이션을 위해 ChatGPT와 함께 구축됩니다. 각 AI에 대해 긴 동영상 강의와 함께 구현 설명서, 미니 PDF, 그리고 파이썬 코드가 제공됩니다. 또한 강의를 완료한 수료자에게는 "Generative AI와 LLMs을 클라우드 컴퓨팅과 함께 사용하는 3시간 추가 강의"를 무료로 제공합니다.
이 강좌에서 제공되는 내용은 다음과 같습니다:
- 초급에서 전문가까지 AI 기술 습득: 다양한 목적을 위한 자기 개선 AI를 코드로 작성하며 학습합니다. 모든 튜토리얼은 빈 페이지에서 코드 작성을 시작하고, 각 코드를 하나하나 작성하며 이해할 수 있도록 돕습니다.
- 간편한 코딩 및 코드 템플릿: 모든 AI는 구글 콜랩에서 구축되므로 라이브러리나 패키지를 설치하는 번거로움 없이 바로 시작할 수 있습니다. 각 AI마다 다운로드 가능한 파이썬 코드 템플릿(.py, .ipynb)을 제공합니다.
- 직관적인 튜토리얼: 복잡한 이론을 일방적으로 강의하는 대신, 왜 그렇게 하는지를 깊이 이해하도록 도와주는 직관적인 튜토리얼을 제공합니다. 이 과정에서는 수학적 복잡성보다는 직관을 중심으로 학습합니다.
- 실제 문제 해결: 5개의 AI 모델을 구축하며 실제 환경에 적합한 AI를 만들어내는 방법을 배우게 됩니다. 연습을 통해 AI를 실제 문제에 적용하는 능력을 기를 수 있습니다.
- 과정 내 지원: AI 분야 전문가들로 이루어진 지원팀이 여러분의 학습 여정을 돕기 위해 48시간 이내에 응답을 제공합니다.
이 강좌는 인공지능, 기계학습, 또는 딥러닝에 관심 있는 모든 사람을 대상으로 합니다. 여러분도 이 흥미로운 AI 세계에 발을 들여놓고, 계속 배우며 AI를 즐길 준비가 되셨나요? 지금 바로 함께 하세요!
배울 내용:
- 7개의 다양한 AI 구축
- 인공지능 이론 이해
- 최신 AI 모델 마스터
- 실제 문제 해결을 위한 AI 활용
- Q-러닝, 심층 Q-러닝, 심층 컨볼루션 Q-러닝, A3C, PPO, SAC 모델 마스터
- LLMs 및 트랜스포머, LoRA와 QLoRA, NLP 챗봇 기법 학습
- LLM 미세 조정 및 지식 증강 학습
- 추가 AI: DDPG, 풀 월드 모델, 진화 전략 및 유전자 알고리즘
강의 요구 사항:
- 고등학교 수학
- 기본 파이썬 지식
이 강의의 대상:
- 인공지능, 기계학습, 딥러닝에 관심 있는 모든 사람
--------------------------------------------------------------------------------------------------
'GreenTam의 생각' 카테고리의 다른 글
| 디지털회로 제작: Microcontroller 개발보드 제작 2 (0) | 2025.05.06 |
|---|---|
| 디지털회로 제작: Microcontroller 개발보드 제작 1 (1) | 2025.04.27 |
| 기계학습, 인공지능 강의 2 : 기계학습 강의 (1) | 2025.04.06 |
| 기계학습, 인공지능 강의 1 : 데이터 과학 강의 (0) | 2025.03.31 |
| 직장인으로서의 단상 2 (1) | 2025.03.28 |